This Case Study is a guest post written by David Buchmann, Software Developer and Project Manager at Liip. Want your company featured on the official Symfony blog? Send a proposal or case study to fabien.potencier@sensiolabs.com
Liip was approached by Migros, the largest retail company in Switzerland. Their challenge was that their product data is managed in several large enterprise systems and databases that are not suitable for real-time access.
Migros has various websites and a mobile application that all need to query data. Liip built the M-API, a Symfony application that gathers the data from the various systems, cleans it up and indexes it with Elasticsearch. This index can be queried in real time through a convenient REST API with JSON and XML output. The M-API handles several million requests per day and does well even during traffic peaks.
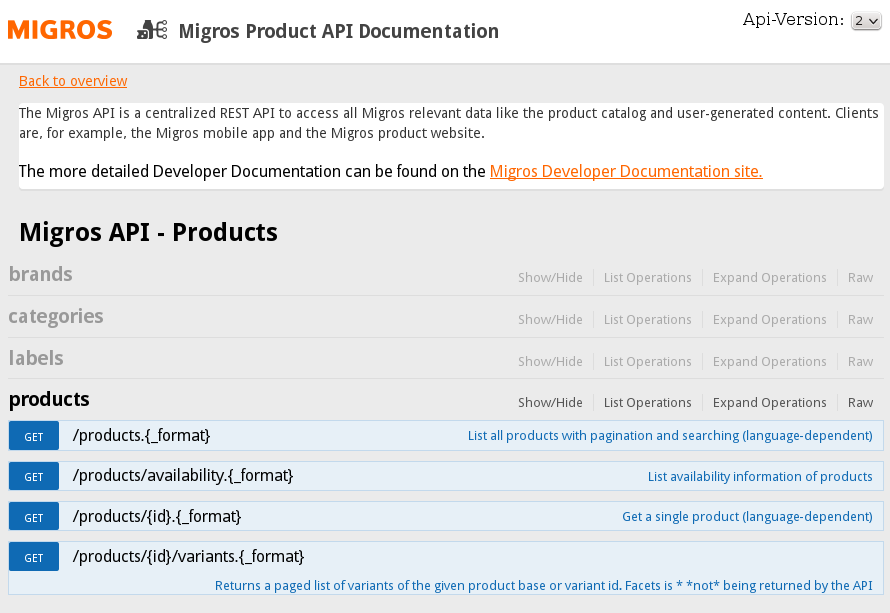
Picture: The API documentation built with NelmioApiDocBundle and swagger.js
API Architecture
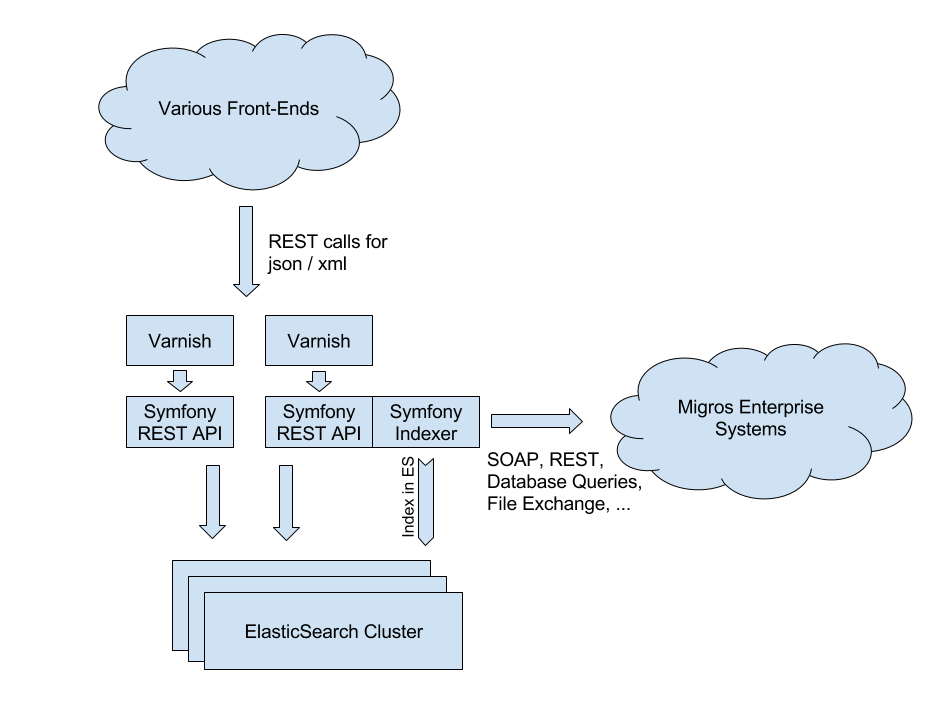
This architecture is redundant and extremely scalable, thus making it possible to simply add more servers, whenever necessary.
The documents in Elasticsearch are large and contain a lot of nested data. We decided to de-normalize all product-related data into each product record to make the lookup faster. When any part of the product information changes, we rebuild the information and re-index that product. The API offers query parameters to control the amount of details desired by the client.
The Symfony application is built around domain model classes for the data. When indexing, the models are populated with data from the external systems and serialized into Elasticsearch. For querying, the models are restored from the Elasticsearch responses and then re-serialized in the requested format and with the requested amount of details. We use the JMS serializer because it can groupfields to control the level of detail and even allow us to support multiple versions of the API from the same data source.
There is, of course, some overhead involved with unserializing the Elasticsearch data and re-serializing it, but the flexibility we gain from this is worth the price. To improve the response times, we run HipHopVM, the alternate PHP implementation done by Facebook to serve the Symfony API. Varnish is configured to go to HHVM by default, falling back to a normal php-fpm + Nginx stack if the HHVM instance fails. We did tests with PHP 5.5 and HHVM that showed us massive performance gains and better scalability. Benchmarks for PHP 7 indicate that it was so improved that HHVM might no longer be necessary.
In front of the M-API, we run Varnish servers to cache results. We use the FOSHttpCacheBundle to manage caching headers and invalidate cached data as needed.
A separate API
The M-API is a separate Symfony application and does not provide any kind of HTML rendering. It is only concerned with collecting data, normalizing and indexing, and delivering information through a REST API. This allows for multi-channel strategies.
Systems building on the M-API include a product catalog website, a mobile application, a customer community platform and various marketing sites about specific sub-sets of the products. Each of these sites can be developed independently, possibly with technologies other than PHP. While the product catalog is a Symfony application, the mobile app is a native IOS and Android app, and many of the marketing sites are done with the Java based CMS Magnolia.
Picture: The product information website is a simple Symfony application with no local database, reading all data from the API.
Thanks to the M-API, such web applications can now focus on their use cases and find the data easily accessible instead of having to re-implement importing the data they need from the various sources. This saves effort and time, while at the same time improving the quality of the data since improvements can be done centrally in the M-API system.
The data gathering is rather complex. The M-API gathers core product data from the central product catalog system and from pricing systems. It prepares images for web access through a CDN. It adds specific meta data like chemical warnings for dangerous products or related products based on data warehouse analysis. It ties into the inventory system to provide availability information and a store locator. But it also takes into account popularity information from customer feedback and from Google analytics.
The development process
Together with the client, Liip chose an agile process. The minimum viable product was simply to provide the product data in JSON and XML format. After some months, the point of having enough functionality available was attained and the M-API went live. In the last 18 months, we constantly added new data sources and additional API end points, releasing in two-week sprints.
Indexing Architecture
During indexing, we de-normalize a lot of data to make querying as fast as possible. For example, the whole breadcrumb of product categories is stored within the product to have the full information available with just one Elasticsearch request. For this, we need a lot of data available during indexing. To make this feasible, we copy all data that is slow to query to the local system (into a MySQL database in our case, but it's essentially a cache with serialized response data.
We could use any persistent storage system) and index from the MySQL database. The indexing process also caches intermediary data in Redis for speedup. These optimizations allow us to further split the process into data gathering and then indexing. Elasticsearch runs as a cluster with several nodes, mainly because of the elevated load of indexing the data.
The main data import runs a series of Symfony commands that update the local MySQL database with the latest information. This is parallelized through workers communicating over RabbitMQ. Once the message queue for data gathering is empty, the second part of indexing into Elasticsearch starts, again using workers to parallel the tasks.
One challenge was that to change the structure of the Elasticsearch index, you need to rebuild it. The data is several hundreds of thousands of documents, so the indexing process takes quite some time. When a schema change occurs, we first deploy the code to the servers without bringing it online, build a new index and, once the new index is ready, switch web requests to the new deployment. The new index is built by copying the documents from the old index, which is a lot faster and puts less strain on the system than re-indexing everything from MySQL.
A great example to demonstrate the potential use of the Symfony framework in the corporate IT industry
Amazing! I want to work with you)! Some questions. How do you measure API performance? What do you think about Kafka as a replacement for RabbitMQ?
Would be cool to add the link to the NelmioApiDocBundle , a very useful bundle.
@Loïc you are right. We've added links to all the bundles. Thanks!
What technology do you use to deploy the application to Production servers?
At the moment, we use capifony to deploy the Symfony application to the servers. It works well, but is discontinued in favor of a new capistrano version 3 plugin: https://github.com/everzet/capifony
But we won't upgrade that anymore, as the servers are migrated to a cloud solution that brings its own git push - based deployment as known from Heroku.
Good approach buddy, i have a similar behavior too, and it works very well :D
@Artem: we haven't looked at Kafka, but we don't have any issues with RabbitMQ so changing anything there is not a priority.
I'm wondering how you stored a whole breadcrumb of product categories within the product to have the full information available for just one Elasticsearch request... Do you store categories' slugs only? What if some of the parent categories' slugs will be changed in the future?