The String Component
Warning: You are browsing the documentation for Symfony 5.x, which is no longer maintained.
Read the updated version of this page for Symfony 8.1 (the current stable version).
The String component provides a single object-oriented API to work with three "unit systems" of strings: bytes, code points and grapheme clusters.
5.0
The String component was introduced in Symfony 5.0.
Installation
1
$ composer require symfony/stringNote
If you install this component outside of a Symfony application, you must
require the vendor/autoload.php file in your code to enable the class
autoloading mechanism provided by Composer. Read
this article for more details.
What is a String?
You can skip this section if you already know what a "code point" or a "grapheme cluster" are in the context of handling strings. Otherwise, read this section to learn about the terminology used by this component.
Languages like English require a very limited set of characters and symbols to display any content. Each string is a series of characters (letters or symbols) and they can be encoded even with the most limited standards (e.g. ASCII).
However, other languages require thousands of symbols to display their contents. They need complex encoding standards such as Unicode and concepts like "character" no longer make sense. Instead, you have to deal with these terms:
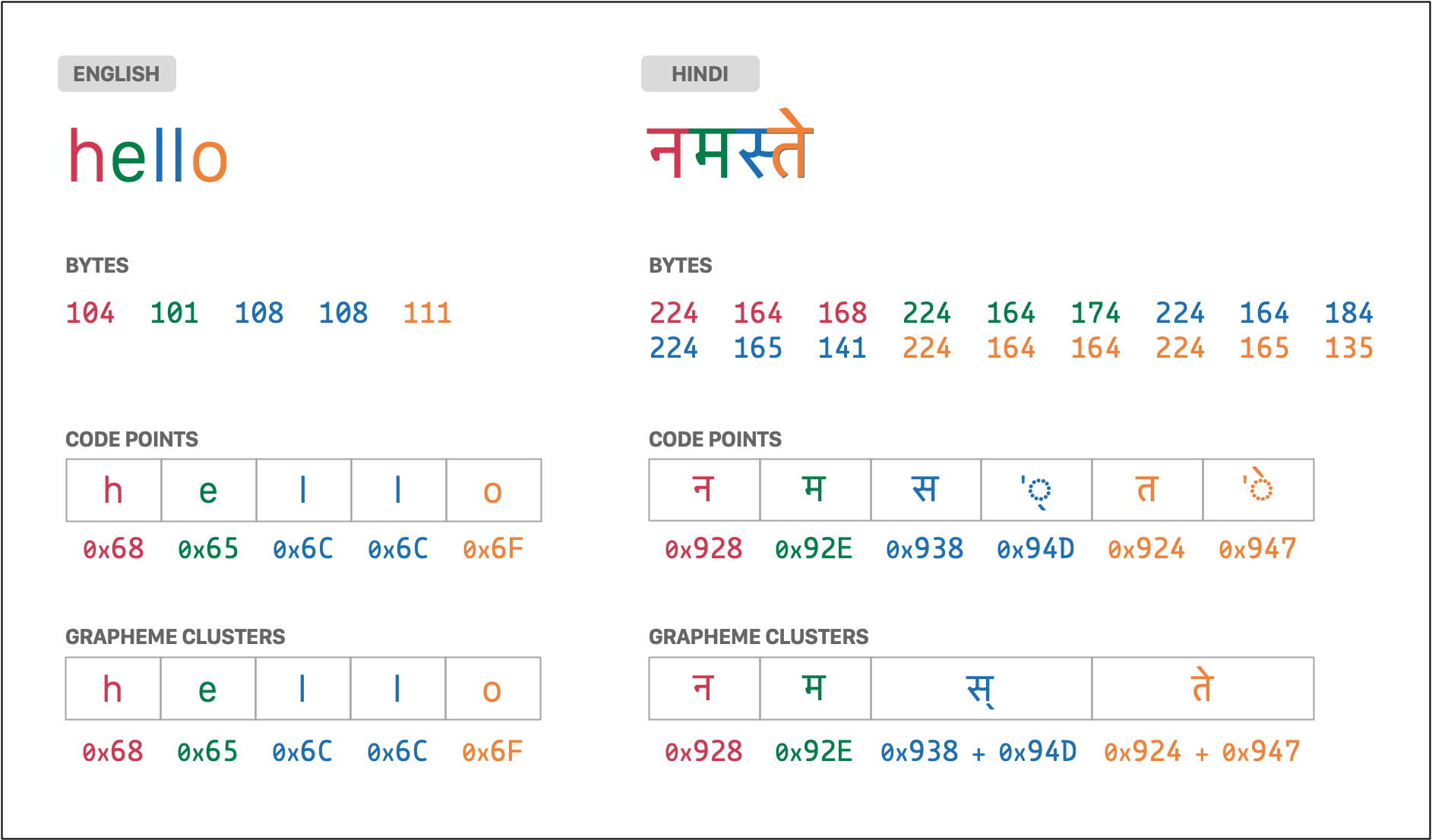
- Code points: they are the atomic units of information. A string is a series
of code points. Each code point is a number whose meaning is given by the
Unicode standard. For example, the English letter
Ais theU+0041code point and the Japanese kanaのis theU+306Ecode point. - Grapheme clusters: they are a sequence of one or more code points which are
displayed as a single graphical unit. For example, the Spanish letter
ñis a grapheme cluster that contains two code points:U+006E=n("latin small letter N") +U+0303=◌̃("combining tilde"). - Bytes: they are the actual information stored for the string contents. Each code point can require one or more bytes of storage depending on the standard being used (UTF-8, UTF-16, etc.).
The following image displays the bytes, code points and grapheme clusters for
the same word written in English (hello) and Hindi (नमस्ते):
Usage
Create a new object of type ByteString, CodePointString or UnicodeString, pass the string contents as their arguments and then use the object-oriented API to work with those strings:
1 2 3 4 5 6 7 8 9 10 11 12
use Symfony\Component\String\UnicodeString;
$text = (new UnicodeString('This is a déjà-vu situation.'))
->trimEnd('.')
->replace('déjà-vu', 'jamais-vu')
->append('!');
// $text = 'This is a jamais-vu situation!'
$content = new UnicodeString('नमस्ते दुनिया');
if ($content->ignoreCase()->startsWith('नमस्ते')) {
// ...
}Method Reference
Methods to Create String Objects
First, you can create objects prepared to store strings as bytes, code points and grapheme clusters with the following classes:
1 2 3 4 5 6 7 8
use Symfony\Component\String\ByteString;
use Symfony\Component\String\CodePointString;
use Symfony\Component\String\UnicodeString;
$foo = new ByteString('hello');
$bar = new CodePointString('hello');
// UnicodeString is the most commonly used class
$baz = new UnicodeString('hello');Use the wrap() static method to instantiate more than one string object:
1 2 3 4 5 6 7
$contents = ByteString::wrap(['hello', 'world']); // $contents = ByteString[]
$contents = UnicodeString::wrap(['I', '❤️', 'Symfony']); // $contents = UnicodeString[]
// use the unwrap method to make the inverse conversion
$contents = UnicodeString::unwrap([
new UnicodeString('hello'), new UnicodeString('world'),
]); // $contents = ['hello', 'world']If you work with lots of String objects, consider using the shortcut functions to make your code more concise:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
// the b() function creates byte strings
use function Symfony\Component\String\b;
// both lines are equivalent
$foo = new ByteString('hello');
$foo = b('hello');
// the u() function creates Unicode strings
use function Symfony\Component\String\u;
// both lines are equivalent
$foo = new UnicodeString('hello');
$foo = u('hello');
// the s() function creates a byte string or Unicode string
// depending on the given contents
use function Symfony\Component\String\s;
// creates a ByteString object
$foo = s("\xfe\xff");
// creates a UnicodeString object
$foo = s('अनुच्छेद');5.1
The s() function was introduced in Symfony 5.1.
There are also some specialized constructors:
1 2 3 4 5 6 7 8 9 10
// ByteString can create a random string of the given length
$foo = ByteString::fromRandom(12);
// by default, random strings use A-Za-z0-9 characters; you can restrict
// the characters to use with the second optional argument
$foo = ByteString::fromRandom(6, 'AEIOU0123456789');
$foo = ByteString::fromRandom(10, 'qwertyuiop');
// CodePointString and UnicodeString can create a string from code points
$foo = UnicodeString::fromCodePoints(0x928, 0x92E, 0x938, 0x94D, 0x924, 0x947);
// equivalent to: $foo = new UnicodeString('नमस्ते');5.1
The second argument of ByteString::fromRandom() was introduced in Symfony 5.1.
Methods to Transform String Objects
Each string object can be transformed into the other two types of objects:
1 2 3 4 5 6 7 8
$foo = ByteString::fromRandom(12)->toCodePointString();
$foo = (new CodePointString('hello'))->toUnicodeString();
$foo = UnicodeString::fromCodePoints(0x68, 0x65, 0x6C, 0x6C, 0x6F)->toByteString();
// the optional $toEncoding argument defines the encoding of the target string
$foo = (new CodePointString('hello'))->toByteString('Windows-1252');
// the optional $fromEncoding argument defines the encoding of the original string
$foo = (new ByteString('さよなら'))->toCodePointString('ISO-2022-JP');If the conversion is not possible for any reason, you'll get an InvalidArgumentException.
There is also a method to get the bytes stored at some position:
1 2 3 4 5 6 7
// ('नमस्ते' bytes = [224, 164, 168, 224, 164, 174, 224, 164, 184,
// 224, 165, 141, 224, 164, 164, 224, 165, 135])
b('नमस्ते')->bytesAt(0); // [224]
u('नमस्ते')->bytesAt(0); // [224, 164, 168]
b('नमस्ते')->bytesAt(1); // [164]
u('नमस्ते')->bytesAt(1); // [224, 164, 174]Methods Related to Length and Whitespace Characters
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
// returns the number of graphemes, code points or bytes of the given string
$word = 'नमस्ते';
(new ByteString($word))->length(); // 18 (bytes)
(new CodePointString($word))->length(); // 6 (code points)
(new UnicodeString($word))->length(); // 4 (graphemes)
// some symbols require double the width of others to represent them when using
// a monospaced font (e.g. in a console). This method returns the total width
// needed to represent the entire word
$word = 'नमस्ते';
(new ByteString($word))->width(); // 18
(new CodePointString($word))->width(); // 4
(new UnicodeString($word))->width(); // 4
// if the text contains multiple lines, it returns the max width of all lines
$text = "<<<END
This is a
multiline text
END";
u($text)->width(); // 14
// only returns TRUE if the string is exactly an empty string (not even whitespace)
u('hello world')->isEmpty(); // false
u(' ')->isEmpty(); // false
u('')->isEmpty(); // true
// removes all whitespace (' \n\r\t\x0C') from the start and end of the string and
// replaces two or more consecutive whitespace characters with a single space (' ') character
u(" \n\n hello \t \n\r world \n \n")->collapseWhitespace(); // 'hello world'Methods to Change Case
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
// changes all graphemes/code points to lower case
u('FOO Bar')->lower(); // 'foo bar'
// when dealing with different languages, uppercase/lowercase is not enough
// there are three cases (lower, upper, title), some characters have no case,
// case is context-sensitive and locale-sensitive, etc.
// this method returns a string that you can use in case-insensitive comparisons
u('FOO Bar')->folded(); // 'foo bar'
u('Die O\'Brian Straße')->folded(); // "die o'brian strasse"
// changes all graphemes/code points to upper case
u('foo BAR')->upper(); // 'FOO BAR'
// changes all graphemes/code points to "title case"
u('foo bar')->title(); // 'Foo bar'
u('foo bar')->title(true); // 'Foo Bar'
// changes all graphemes/code points to camelCase
u('Foo: Bar-baz.')->camel(); // 'fooBarBaz'
// changes all graphemes/code points to snake_case
u('Foo: Bar-baz.')->snake(); // 'foo_bar_baz'
// other cases can be achieved by chaining methods. E.g. PascalCase:
u('Foo: Bar-baz.')->camel()->title(); // 'FooBarBaz'The methods of all string classes are case-sensitive by default. You can perform
case-insensitive operations with the ignoreCase() method:
1 2
u('abc')->indexOf('B'); // null
u('abc')->ignoreCase()->indexOf('B'); // 1Methods to Append and Prepend
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
// adds the given content (one or more strings) at the beginning/end of the string
u('world')->prepend('hello'); // 'helloworld'
u('world')->prepend('hello', ' '); // 'hello world'
u('hello')->append('world'); // 'helloworld'
u('hello')->append(' ', 'world'); // 'hello world'
// adds the given content at the beginning of the string (or removes it) to
// make sure that the content starts exactly with that content
u('Name')->ensureStart('get'); // 'getName'
u('getName')->ensureStart('get'); // 'getName'
u('getgetName')->ensureStart('get'); // 'getName'
// this method is similar, but works on the end of the content instead of on the beginning
u('User')->ensureEnd('Controller'); // 'UserController'
u('UserController')->ensureEnd('Controller'); // 'UserController'
u('UserControllerController')->ensureEnd('Controller'); // 'UserController'
// returns the contents found before/after the first occurrence of the given string
u('hello world')->before('world'); // 'hello '
u('hello world')->before('o'); // 'hell'
u('hello world')->before('o', true); // 'hello'
u('hello world')->after('hello'); // ' world'
u('hello world')->after('o'); // ' world'
u('hello world')->after('o', true); // 'o world'
// returns the contents found before/after the last occurrence of the given string
u('hello world')->beforeLast('o'); // 'hello w'
u('hello world')->beforeLast('o', true); // 'hello wo'
u('hello world')->afterLast('o'); // 'rld'
u('hello world')->afterLast('o', true); // 'orld'Methods to Pad and Trim
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
// makes a string as long as the first argument by adding the given
// string at the beginning, end or both sides of the string
u(' Lorem Ipsum ')->padBoth(20, '-'); // '--- Lorem Ipsum ----'
u(' Lorem Ipsum')->padStart(20, '-'); // '-------- Lorem Ipsum'
u('Lorem Ipsum ')->padEnd(20, '-'); // 'Lorem Ipsum --------'
// repeats the given string the number of times passed as argument
u('_.')->repeat(10); // '_._._._._._._._._._.'
// removes the given characters (default: whitespace characters) from the beginning and end of a string
u(' Lorem Ipsum ')->trim(); // 'Lorem Ipsum'
u('Lorem Ipsum ')->trim('m'); // 'Lorem Ipsum '
u('Lorem Ipsum')->trim('m'); // 'Lorem Ipsu'
u(' Lorem Ipsum ')->trimStart(); // 'Lorem Ipsum '
u(' Lorem Ipsum ')->trimEnd(); // ' Lorem Ipsum'
// removes the given content from the start/end of the string
u('file-image-0001.png')->trimPrefix('file-'); // 'image-0001.png'
u('file-image-0001.png')->trimPrefix('image-'); // 'file-image-0001.png'
u('file-image-0001.png')->trimPrefix('file-image-'); // '0001.png'
u('template.html.twig')->trimSuffix('.html'); // 'template.html.twig'
u('template.html.twig')->trimSuffix('.twig'); // 'template.html'
u('template.html.twig')->trimSuffix('.html.twig'); // 'template'
// when passing an array of prefix/suffix, only the first one found is trimmed
u('file-image-0001.png')->trimPrefix(['file-', 'image-']); // 'image-0001.png'
u('template.html.twig')->trimSuffix(['.twig', '.html']); // 'template.html'5.4
The trimPrefix() and trimSuffix() methods were introduced in Symfony 5.4.
Methods to Search and Replace
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
// checks if the string starts/ends with the given string
u('https://symfony.com')->startsWith('https'); // true
u('report-1234.pdf')->endsWith('.pdf'); // true
// checks if the string contents are exactly the same as the given contents
u('foo')->equalsTo('foo'); // true
// checks if the string content match the given regular expression.
u('avatar-73647.png')->match('/avatar-(\d+)\.png/');
// result = ['avatar-73647.png', '73647', null]
// You can pass flags for preg_match() as second argument. If PREG_PATTERN_ORDER
// or PREG_SET_ORDER are passed, preg_match_all() will be used.
u('206-555-0100 and 800-555-1212')->match('/\d{3}-\d{3}-\d{4}/', \PREG_PATTERN_ORDER);
// result = [['206-555-0100', '800-555-1212']]
// checks if the string contains any of the other given strings
u('aeiou')->containsAny('a'); // true
u('aeiou')->containsAny(['ab', 'efg']); // false
u('aeiou')->containsAny(['eio', 'foo', 'z']); // true
// finds the position of the first occurrence of the given string
// (the second argument is the position where the search starts and negative
// values have the same meaning as in PHP functions)
u('abcdeabcde')->indexOf('c'); // 2
u('abcdeabcde')->indexOf('c', 2); // 2
u('abcdeabcde')->indexOf('c', -4); // 7
u('abcdeabcde')->indexOf('eab'); // 4
u('abcdeabcde')->indexOf('k'); // null
// finds the position of the last occurrence of the given string
// (the second argument is the position where the search starts and negative
// values have the same meaning as in PHP functions)
u('abcdeabcde')->indexOfLast('c'); // 7
u('abcdeabcde')->indexOfLast('c', 2); // 7
u('abcdeabcde')->indexOfLast('c', -4); // 2
u('abcdeabcde')->indexOfLast('eab'); // 4
u('abcdeabcde')->indexOfLast('k'); // null
// replaces all occurrences of the given string
u('http://symfony.com')->replace('http://', 'https://'); // 'https://symfony.com'
// replaces all occurrences of the given regular expression
u('(+1) 206-555-0100')->replaceMatches('/[^A-Za-z0-9]++/', ''); // '12065550100'
// you can pass a callable as the second argument to perform advanced replacements
u('123')->replaceMatches('/\d/', function ($match) {
return '['.$match[0].']';
}); // result = '[1][2][3]'5.1
The containsAny() method was introduced in Symfony 5.1.
Methods to Join, Split, Truncate and Reverse
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
// uses the string as the "glue" to merge all the given strings
u(', ')->join(['foo', 'bar']); // 'foo, bar'
// breaks the string into pieces using the given delimiter
u('template_name.html.twig')->split('.'); // ['template_name', 'html', 'twig']
// you can set the maximum number of pieces as the second argument
u('template_name.html.twig')->split('.', 2); // ['template_name', 'html.twig']
// returns a substring which starts at the first argument and has the length of the
// second optional argument (negative values have the same meaning as in PHP functions)
u('Symfony is great')->slice(0, 7); // 'Symfony'
u('Symfony is great')->slice(0, -6); // 'Symfony is'
u('Symfony is great')->slice(11); // 'great'
u('Symfony is great')->slice(-5); // 'great'
// reduces the string to the length given as argument (if it's longer)
u('Lorem Ipsum')->truncate(3); // 'Lor'
u('Lorem Ipsum')->truncate(80); // 'Lorem Ipsum'
// the second argument is the character(s) added when a string is cut
// (the total length includes the length of this character(s))
u('Lorem Ipsum')->truncate(8, '…'); // 'Lorem I…'
// if the third argument is false, the last word before the cut is kept
// even if that generates a string longer than the desired length
u('Lorem Ipsum')->truncate(8, '…', false); // 'Lorem Ipsum'5.1
The third argument of truncate() was introduced in Symfony 5.1.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// breaks the string into lines of the given length
u('Lorem Ipsum')->wordwrap(4); // 'Lorem\nIpsum'
// by default it breaks by white space; pass TRUE to break unconditionally
u('Lorem Ipsum')->wordwrap(4, "\n", true); // 'Lore\nm\nIpsu\nm'
// replaces a portion of the string with the given contents:
// the second argument is the position where the replacement starts;
// the third argument is the number of graphemes/code points removed from the string
u('0123456789')->splice('xxx'); // 'xxx'
u('0123456789')->splice('xxx', 0, 2); // 'xxx23456789'
u('0123456789')->splice('xxx', 0, 6); // 'xxx6789'
u('0123456789')->splice('xxx', 6); // '012345xxx'
// breaks the string into pieces of the length given as argument
u('0123456789')->chunk(3); // ['012', '345', '678', '9']
// reverses the order of the string contents
u('foo bar')->reverse(); // 'rab oof'
u('さよなら')->reverse(); // 'らなよさ'5.1
The reverse() method was introduced in Symfony 5.1.
Methods Added by ByteString
These methods are only available for ByteString objects:
1 2 3
// returns TRUE if the string contents are valid UTF-8 contents
b('Lorem Ipsum')->isUtf8(); // true
b("\xc3\x28")->isUtf8(); // falseMethods Added by CodePointString and UnicodeString
These methods are only available for CodePointString and UnicodeString
objects:
1 2 3 4 5 6 7 8 9 10 11
// transliterates any string into the latin alphabet defined by the ASCII encoding
// (don't use this method to build a slugger because this component already provides
// a slugger, as explained later in this article)
u('नमस्ते')->ascii(); // 'namaste'
u('さよなら')->ascii(); // 'sayonara'
u('спасибо')->ascii(); // 'spasibo'
// returns an array with the code point or points stored at the given position
// (code points of 'नमस्ते' graphemes = [2344, 2350, 2360, 2340]
u('नमस्ते')->codePointsAt(0); // [2344]
u('नमस्ते')->codePointsAt(2); // [2360]Unicode equivalence is the specification by the Unicode standard that
different sequences of code points represent the same character. For example,
the Swedish letter å can be a single code point (U+00E5 = "latin small
letter A with ring above") or a sequence of two code points (U+0061 =
"latin small letter A" + U+030A = "combining ring above"). The
normalize() method allows to pick the normalization mode:
1 2 3 4 5 6
// these encode the letter as a single code point: U+00E5
u('å')->normalize(UnicodeString::NFC);
u('å')->normalize(UnicodeString::NFKC);
// these encode the letter as two code points: U+0061 + U+030A
u('å')->normalize(UnicodeString::NFD);
u('å')->normalize(UnicodeString::NFKD);Lazy-loaded Strings
Sometimes, creating a string with the methods presented in the previous sections is not optimal. For example, consider a hash value that requires certain computation to obtain and which you might end up not using it.
In those cases, it's better to use the LazyString class that allows to store a string whose value is only generated when you need it:
1 2 3 4 5 6 7 8 9
use Symfony\Component\String\LazyString;
$lazyString = LazyString::fromCallable(function () {
// Compute the string value...
$value = ...;
// Then return the final value
return $value;
});The callback will only be executed when the value of the lazy string is
requested during the program execution. You can also create lazy strings from a
Stringable object:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
class Hash implements \Stringable
{
public function __toString(): string
{
return $this->computeHash();
}
private function computeHash(): string
{
// Compute hash value with potentially heavy processing
$hash = ...;
return $hash;
}
}
// Then create a lazy string from this hash, which will trigger
// hash computation only if it's needed
$lazyHash = LazyString::fromStringable(new Hash());5.1
The LazyString class was introduced in Symfony 5.1.
Slugger
In some contexts, such as URLs and file/directory names, it's not safe to use any Unicode character. A slugger transforms a given string into another string that only includes safe ASCII characters:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
use Symfony\Component\String\Slugger\AsciiSlugger;
$slugger = new AsciiSlugger();
$slug = $slugger->slug('Wôrķšƥáçè ~~sèťtïñğš~~');
// $slug = 'Workspace-settings'
// you can also pass an array with additional character substitutions
$slugger = new AsciiSlugger('en', ['en' => ['%' => 'percent', '€' => 'euro']]);
$slug = $slugger->slug('10% or 5€');
// $slug = '10-percent-or-5-euro'
// if there is no symbols map for your locale (e.g. 'en_GB') then the parent locale's symbols map
// will be used instead (i.e. 'en')
$slugger = new AsciiSlugger('en_GB', ['en' => ['%' => 'percent', '€' => 'euro']]);
$slug = $slugger->slug('10% or 5€');
// $slug = '10-percent-or-5-euro'
// for more dynamic substitutions, pass a PHP closure instead of an array
$slugger = new AsciiSlugger('en', function ($string, $locale) {
return str_replace('❤️', 'love', $string);
});5.1
The feature to define additional substitutions was introduced in Symfony 5.1.
5.2
The feature to use a PHP closure to define substitutions was introduced in Symfony 5.2.
5.3
The feature to fallback to the parent locale's symbols map was introduced in Symfony 5.3.
The separator between words is a dash (-) by default, but you can define
another separator as the second argument:
1 2
$slug = $slugger->slug('Wôrķšƥáçè ~~sèťtïñğš~~', '/');
// $slug = 'Workspace/settings'The slugger transliterates the original string into the Latin script before applying the other transformations. The locale of the original string is detected automatically, but you can define it explicitly:
1 2 3 4 5 6
// this tells the slugger to transliterate from Korean ('ko') language
$slugger = new AsciiSlugger('ko');
// you can override the locale as the third optional parameter of slug()
// e.g. this slugger transliterates from Persian ('fa') language
$slug = $slugger->slug('...', '-', 'fa');In a Symfony application, you don't need to create the slugger yourself. Thanks to service autowiring, you can inject a slugger by type-hinting a service constructor argument with the SluggerInterface. The locale of the injected slugger is the same as the request locale:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
use Symfony\Component\String\Slugger\SluggerInterface;
class MyService
{
private $slugger;
public function __construct(SluggerInterface $slugger)
{
$this->slugger = $slugger;
}
public function someMethod()
{
$slug = $this->slugger->slug('...');
}
}Inflector
5.1
The inflector feature was introduced in Symfony 5.1.
In some scenarios such as code generation and code introspection, you need to
convert words from/to singular/plural. For example, to know the property
associated with an adder method, you must convert from plural
(addStories() method) to singular ($story property).
Most human languages have simple pluralization rules, but at the same time they
define lots of exceptions. For example, the general rule in English is to add an
s at the end of the word (book -> books) but there are lots of
exceptions even for common words (woman -> women, life -> lives,
news -> news, radius -> radii, etc.)
This component provides an EnglishInflector class to convert English words from/to singular/plural with confidence:
1 2 3 4 5 6 7 8 9 10 11
use Symfony\Component\String\Inflector\EnglishInflector;
$inflector = new EnglishInflector();
$result = $inflector->singularize('teeth'); // ['tooth']
$result = $inflector->singularize('radii'); // ['radius']
$result = $inflector->singularize('leaves'); // ['leaf', 'leave', 'leaff']
$result = $inflector->pluralize('bacterium'); // ['bacteria']
$result = $inflector->pluralize('news'); // ['news']
$result = $inflector->pluralize('person'); // ['persons', 'people']The value returned by both methods is always an array because sometimes it's not possible to determine a unique singular/plural form for the given word.
Note
Symfony also provides a FrenchInflector and an InflectorInterface if you need to implement your own inflector.