Anteriormente en symfony
Con las interacciones AJAX, los servicios web, los feeds RSS, muchas características de administración y un número de usuarios creciente, askeet tiene casi todo lo que puede pedir una aplicación web 2.0. La comunidad symfony debatió qué se podía añadir a todo eso para hacer de askeet una killer application real.
Alguna de las sugerencias incluían características que estaban planeadas inicialmente. Otros pensaban en pequeñas mejoras que se harían en un par de minutos, y probablemente serán incluidas pronto después del lanzamiento del la versión 1.0. Askeet pretende ser una aplicación de código abierta real, y puedes empezar a plantear tíquets o proposiciones de evolución en el sistema trac de askeet. También puedes contribuir con parches y adaptaciones o extender la aplicación a tu gusto. Pero por favor espera unos días más, ya que el calendario de symfony tiene más sorpresas antes de Navidad.
Cómo construir un motor de búsqueda?
La sugerencia más popular en el 21-avo día ha resultado ser un motor de búsqueda.
Si la extensión Zsearch (una implementación en PHP del motor de búsqueda Lucene de la fundación Apache) fuera liberada por Zend sería muy fácil implementarlo. Desafortunadamente, Zend parece que está tardando más tiempo de lo esperado para lanzar su framework PHP, por lo tanto necesitamos encontrar otra solución.
Integrando una librería externa (como, por ejemplo, mnoGoSearch) nos llevaría probablemente más de una hora, y muchas adaptaciones personalizadas serían necesarias para obtener un buen resultado para el contenido especifico de askeet. Además, librerías de búsqueda externas son, a menudo, dependientes de la plataforma y la base de datos, y no todas son de código abierto y eso no es lo que queremos para el askeet.
La base de datos MySQL ofrece una indexación en texto completo y búsqueda por contenido del texto, pero estas características están restringidas a las tablas MyISAM. Una vez más, basar nuestro motor de búsqueda en un componente que sea dependiente de la base de datos limitaría los posibles usos de la aplicación askeet, y queremos hacer todo lo posible para garantizar la compatibilidad que tiene.
La única alternativa que nos queda es desarrollar un motor de búsqueda a texto completo en PHP nosotros mismos. Y tenemos menos de una hora, por lo tanto sería mejor que empezáramos.
Palabra índice
El primer paso es crear un índice de búsqueda. El índice se puede ver como una tabla indexando todas las apariciones de una palabra concreta. Por ejemplo si la pregunta #34 tiene las siguientes características:
- Título: Cual es el mejor signo del Zodíaco para mi hijo?
- Cuerpo: Mi marido no se preocupa por los signos del Zodíaco para nuestro próximo hijo, pero ya tenemos una chica que es Cáncer y un chico que es Aries, y se portan fatal entre si. My madre no mostró ninguna preferencia, por lo tanto tengo libre elección para escoger el signo del Zodíaco para mi siguiente crío. Que opináis?
- Etiquetas: zodiaco, vida real, familia, críos, signo, astrología, signos
Se tiene que crear un índice para listar las palabras de esta pregunta para que el motor de búsqueda pueda encontrarla.
Tabla índice
El índice tiene que ser:
| id | palabra | apariciones |
|---|---|---|
| 34 | sign | 4 |
| 34 | zodiac | 4 |
| 34 | child | 2 |
| 34 | hell | 1 |
| 34 | ... | ... |
La tabla nueva SearchIndex se ha añadido al schema.xml de askeet antes de reconstruir el modelo:
[xml]
El atributo onDelete se asegura que el borrado de una pregunta también borrará todos las entradas en la tabla SearchIndex relacionadas con esta pregunta, como contábamos ayer
Dividiendo frases en palabras
El contenido de entrada que será usado para construir el índice es un conjunto de frases (títulos de pregunta y cuerpo) y etiquetas. Lo que queremos finalmente es una lista de palabras. Esto significa que necesitamos dividir las frases en palabras, ignorando todos los signos de puntuación, números y poniendo todas las palabras en minúscula. La función de PHP str_word_count() hará el trabajo
[php] // dividir en palabras $words = str_word_count(strtolower($phrase), 1); ...
Palabras excluidas
Algunas palabras como "a", "de", "el", "yo", "esto", "tú" y "y" tienen que ser ignoradas cuando se indexa el contenido. Esto es porqué no tienen valor distintivo, aparecen en casi cualquier texto, y hacen ir la búsqueda más lenta además de devolver muchos resultados erróneos que no tienen que ver con la búsqueda del usuario. Son conocidas como stop words (N.T.: traducido como palabras excluidas). Las stop words son específicas para cada lenguaje.
Para el motor de búsqueda de askeet, usaremos una lista personalizada de stop words. Añade el siguiente método en la clase askeet/lib/myTools.class.php:
[php] public static function removeStopWordsFromArray($words) { $stop_words = array( 'i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', 'her', 'hers', 'herself', 'it', 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', ); return array_diff($words, $stop_words); }
Lexema
La primera cosa que deberías notar en la pregunta de ejemplo anterior es que las palabras con el mismo lexema deberían verse como una sola. 'Críos' debería incrementar la aparición (el peso) de 'crío', igual que 'signo' lo haría para 'signos'. Por lo tanto antes de indexar palabras, tienen que ser reducidas al máximo común divisor, y en el vocabulario lingüístico eso se llama stem, o reducir la palabra a su lexema.
Hay muchas reglas para reducir una palabra a su lexema y estas reglas son todas dependientes del lenguaje. Uno de las mejores técnicas de stemming para el Inglés se llama the Porter Stemming Algorithm y, como somos afortunados, has sido programada en PHP5 en un script de código abierto disponible en tartarus.org.
La clase PorterStemmer proporciona el método ::stem($palabra) que es perfecto para nuestras necesidades. Por tanto podemos escribir un método, todavía en myTools.class.php, que transforme una frase en un array de lexemas:
[php] public static function stemPhrase($phrase) { // dividimos en palabras $words = str_word_count(strtolower($phrase), 1); // ignoramos "stop words" $words = myTools::removeStopWordsFromArray($words); // transformamos las palabras en lexemas $stemmed_words = array(); foreach ($words as $word) { // ignore 1 and 2 letter words if (strlen($word) <= 2) { continue; } $stemmed_words[] = PorterStemmer::stem($word, true); } return $stemmed_words; }
Por su puesto, tienes que poner la clase PorterStemmer.class.php en el directorio askeet/lib/ para que esto funcione.
Dando peso a las palabras
Los resultados de las búsquedas tienen que aparecer en un orden de pertinencia. Las preguntas que están más estrechamente ligadas a las palabras introducidas por el usuario tienen que aparecer primero. Pero cómo podemos traducir esta idea de pertinencia en un algoritmo? Vamos a escribir algunos principios básicos:
- Si una palabra buscada aparece en el título de una pregunta, esta pregunta tiene que aparecer antes en una búsqueda que otra en el que la palabra sólo aparece en el cuerpo
- Si una palabra buscada aparece dos veces en el contenido de una pregunta, el resultado de la búsqueda debería mostrar esta pregunta antes que otras en donde la palabra sólo aparece una vez
Es por eso que tenemos que dar peso a las palabras según la parte de la pregunta de la que vengan. Ya que los factores de peso tienen que ser fácilmente accesibles para cambiarlos si queremos afinar nuestro algoritmo de búsqueda, los pondremos en un fichero de configuración de la aplicación:
(askeet/apps/frontend/config/app.yml):
all: ... search: body_weight: 1 title_weight: 2 tag_weight: 3
Para aplicar el peso a una palabra, simplemente tenemos que repetir el contenido de una cadena tantas veces como el factor de peso de su origen:
[php] ... // cuerpo de la pregunta $raw_text = str_repeat(' '.strip_tags($question->getHtmlBody()), sfConfig::get('app_search_body_weight'));
// título de la pregunta $raw_text .= str_repeat(' '.$question->getTitle(), sfConfig::get('app_search_title_weight')); ...
El peso básico de las palabras viene dado por el número de ocurrencias en el texto. La función de PHP array_count_values() nos ayudará con esto:
[php] ... // stemming de la frase $stemmed_words = myTools::stemPhrase($raw_text);
// palabras únicas con pesos $words = array_count_values($stemmed_words);
Actualizando el índice
El índice tiene que ser actualizado cada vez que una pregunta, etiqueta o respuesta es añadida. La arquitectura MVC lo pone fácil, y ya has visto cómo sobreescribir el método save() en una clase del Modelo en una transacción, por ejemplo durante el día 4. Por lo tanto lo siguiente no tendría que sorprendente. Abre el archivo askeet/lib/model/Question.php y añade:
[php] public function save($con = null) { $con = sfContext::getInstance()->getDatabaseConnection('propel'); try { $con->begin(); $ret = parent::save($con); $this->updateSearchIndex(); $con->commit(); return $ret; } catch (Exception $e) { $con->rollback(); throw $e; } } public function updateSearchIndex() { // borra las entradas de los índices de búsqueda existentes de esta prgunta $c = new Criteria(); $c->add(SearchIndexPeer::QUESTION_ID, $this->getId()); SearchIndexPeer::doDelete($c); // creamos una nueva entrada por cada una de las palabras de la pregunta foreach ($this->getWords() as $word => $weight) { $index = new SearchIndex(); $index->setQuestionId($this->getId()); $index->setWord($word); $index->setWeight($weight); $index->save(); } }
public function getWords()
{
// cuerpo
$raw_text = str_repeat(' '.strip_tags($this->getHtmlBody()), sfConfig::get('app_search_body_weight'));
// título
$raw_text .= str_repeat(' '.$this->getTitle(), sfConfig::get('app_search_title_weight'));
// stemming del título y el cuerpo
$stemmed_words = myTools::stemPhrase($raw_text);
// palabras únicas con pesos
$words = array_count_values($stemmed_words);
// añadir etiquetas
$max = 0;
foreach ($this->getPopularTags(20) as $tag => $count)
{
if (!$max)
{
$max = $count;
}
$stemmed_tag = PorterStemmer::stem($tag);
if (!isset($words[$stemmed_tag]))
{
$words[$stemmed_tag] = 0;
}
$words[$stemmed_tag] += ceil(($count / $max) * sfConfig::get('app_search_tag_weight'));
}
return $words;
}
También tenemos que actualizar el índice de una pregunta cada vez que se le añade una etiqueta a ella, por lo tanto, también tenemos que sobreescribir el método save() del objeto etiqueta del modelo:
[php] public function save($con = null) { $con = sfContext::getInstance()->getDatabaseConnection('propel'); try { $con->begin(); $ret = parent::save($con); $this->getQuestion()->updateSearchIndex(); $con->commit(); return $ret; } catch (Exception $e) { $con->rollback(); throw $e; } }
Probar el constructor del índice
El índice está preparado para ser construido. Inicialízalo añadiendo datos a la base otra vez:
$ php batch/load_data.php
Puedes inspeccionar la tabla SearchIndex para comprobar que la creación del índice ha ido bien:
id | word | weight ---|------------|------- 10 | blog | 6 9 | offer | 4 8 | girl | 3 8 | rel | 3 8 | activ | 3 10 | activ | 3 9 | present | 3 9 | reallif | 3 11 | test | 3 12 | test | 3 13 | test | 3 8 | shall | 3 8 | tonight | 2 8 | girlfriend | 2 .. | ..... | ..
La función de búsqueda
Y o O?
Queremos que la función de búsqueda controle las búsquedas 'Y' y 'O'. Por ejemplo, si un usuario entra 'zodíaco familiar', el (ella?) tiene que tener la opción de buscar sólo las preguntas en las que ambas palabras aparecen (eso es una 'Y'), o para todas las preguntas que como mínimo sólo aparece una (esto es una 'O'). El problema es que estas dos opciones nos llevan a dos preguntas diferentes:
[sql] // pregunta 'O' SELECT DISTINCT question_id, COUNT() AS nb, SUM(weight) AS total_weight FROM ask_search_index WHERE (word = "family" OR word = "zodiac") GROUP BY question_id ORDER BY nb DESC, total_weight DESC // pregunta 'Y' SELECT DISTINCT question_id, COUNT() AS nb, SUM(weight) AS total_weight FROM ask_search_index WHERE (word = "family" OR word = "zodiac") GROUP BY question_id HAVING nb = 2 ORDER BY nb DESC, total_weight DESC
Gracias a la palabra reservada HAVING (explicada, por ejemplo en w3schools), la pregunta SQL AND es sólo una línea más larga que la 'O'. Ya que el 'GROUP BYestá en la columnaid, y además sólo hay una ocurrencia del índice para una palabra dada en una pregunta, si unaquestion_id` se devuelve dos veces, es porque la pregunta contiene ambos términos, 'familiar' y 'zodíaco'. Efectivo, no?
El método de búsqueda (search)
Para que la búsqueda funcione, necesitamos aplicar el mismo tratamiento a la frase buscada que al contenido, por lo tanto las palabras entradas por el usuario son reducidas a lexemas igual que en el índice. Ya que devuelve un conjunto de preguntas sin ninguna restricción, hemos decidido implementarlo cómo un método del objeto QuestionPeer:
Los resultados de las búsquedas necesitan ser paginados. Ya que usamos peticiones complejas, el objeto sdPropelPager no puede ser usado aquí, por lo tanto haremos una paginación manual, usando un offset.
Hay una cosa más que recordar: askeet está hecho para funcionar con universos (eso fue el tema del tutorial del eighteenth day). Eso significa que una función de búsqueda tiene que devolver sólo las preguntas etiquetadas con la app_permanent_tag (etiqueta permanente de aplicación) si el usuario está navegando en un universo de askeet.
Todas esas condiciones hacen que la pregunta SQL sea un poco más difícil de leer, pero no muy distinta de las otras mostradas anteriormente:
[php] public static function search($phrase, $exact = false, $offset = 0, $max = 10) { $words = array_values(myTools::stemPhrase($phrase)); $nb_words = count($words); if (!$words) { return array(); } $con = sfContext::getInstance()->getDatabaseConnection('propel'); // Definimios la pregunta base $query = ' SELECT DISTINCT '.SearchIndexPeer::QUESTION_ID.', COUNT(*) AS nb, SUM('.SearchIndexPeer::WEIGHT.') AS total_weight FROM '.SearchIndexPeer::TABLE_NAME; if (sfConfig::get('app_permanent_tag')) { $query .= ' WHERE '; } else { $query .= ' LEFT JOIN '.QuestionTagPeer::TABLE_NAME.' ON '.QuestionTagPeer::QUESTION_ID.' = '.SearchIndexPeer::QUESTION_ID.' WHERE '.QuestionTagPeer::NORMALIZED_TAG.' = ? AND '; } $query .= ' ('.implode(' OR ', array_fill(0, $nb_words, SearchIndexPeer::WORD.' = ?')).') GROUP BY '.SearchIndexPeer::QUESTION_ID; // pregunta 'Y' if ($exact) { $query .= ' HAVING nb = '.$nb_words; } $query .= ' ORDER BY nb DESC, total_weight DESC'; // preparamos la sentencia $stmt = $con->prepareStatement($query); $stmt->setOffset($offset); $stmt->setLimit($max); $placeholder_offset = 1; if (sfConfig::get('app_permanent_tag')) { $stmt->setString(1, sfConfig::get('app_permanent_tag')); $placeholder_offset = 2; } for ($i = 0; $i < $nb_words; $i++) { $stmt->setString($i + $placeholder_offset, $words[$i]); } $rs = $stmt->executeQuery(ResultSet::FETCHMODE_NUM); // Recojemos los resultados $questions = array(); while ($rs->next()) { $questions[] = self::retrieveByPK($rs->getInt(1)); } return $questions; }
El método devuelve una lista de objetos Question, ordenados por importancia
El formulario de búsqueda
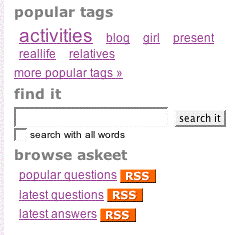
El formulario de búsqueda tienes que estar siempre disponible, por lo tanto hemos elegido ponerlo en la barra lateral. Como hay dos barras laterales distintas, tendrían que incluir el mismo elemento parcial:
[php] // añade a defaultSuccess.php y questionSuccess.php en askeet/apps/frontend/modules/sidebar/templates/
find it
// crea el siguiente fragmento askeet/apps/frontend/modules/question/templates/_search.php get('search')), array('style' => 'width: 150px')) ?> get('search_all')) ?>
La regla @search_question tiene que ser definida en routing.yml:
search_question: url: /search/* param: { module: question, action: search }
Sabes lo que hace la acción question/search? Casi nada, ya que la mayor parte del trabajo se hace en el método QuestionPeer::search() descrito anteriormente:
[php] public function executeSearch () { if ($this->getRequestParameter('search')) { $this->questions = QuestionPeer::search($this->getRequestParameter('search'), $this->getRequestParameter('search_all', false), ($this->getRequestParameter('page', 1) - 1) * sfConfig::get('app_search_results_max'), sfConfig::get('app_search_results_max')); } else { $this->redirect('@homepage'); } }
La acción tiene que traducir un parámetro de petición de página en un offset para el método search(). El app_search_results_max es el número de resultados por página, y como viene siendo habitual, es una parámetro de aplicación definido en el archivo de app.yml:
all: search: results_max: 10
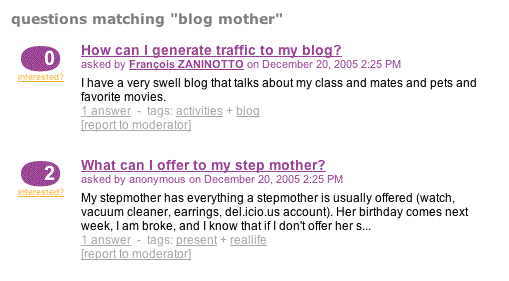
Mostrar el resultado de la búsqueda
La parte más difícil del trabajo ya está hecha, sólo tenemos que mostrar el resultado en askeet/apps/frontend/modules/question/templates/searchSuccess.php. Ya que no hemos implementado una paginación real para mantener el peso de la pregunta, la plantilla no tienen información del número total de resultados. La paginación sólo mostrará un enlace a más resultados al final de la lista de resultados si el número de resultados es igual al máximo de resultados por página:
[php]
questions matching "get('search')) ?>"
$question)) ?> get('page') > 1 && !count($questions)): ?>
Ah, sí, esa es la sorpresa final. Hemos refactorizado un poco la plantilla de la pregunta para crear el bloque _questio_block.php ya que el código fue rehusado en más de un lugar. Hecha una ojeada a este fragmento en el repositorio de código, no hay nada nuevo en él. Pero nos ayuda a mantener el código limpio.
Nos vemos mañana
Nos ha llevado una hora crear un buen motor de búsqueda perfectamente adaptado a nuestras necesidades. És pequeño, rápido y eficiente. Devuelve resultados pertinentes. Quieres integrar una librería para hacer el mismo trabajo sin ninguna posibilidad de ajustarla?
Si no, probablemente empieces a pensar siguiendo el camino de symfony. Si has entendido este tutorial, probablemente puedas añadir la indexación de las respuestas a una pregunta. Preguntas y sugerencias son bienvenidas en el fórum de askeet. Y principalmente no crees nuevas preguntas en askeet si una pregunta parecida ya se ha hecho: ahora hay un motor de búsqueda, no tienes excusa!
This work is licensed under the Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 Unported License license.