復習
AJAXインタラクションとRSSフィード、十分なサイト管理機能によって askeetはWeb 2.0のアプリケーションが求める機能をほとんど持ちました。 askeetを本当のキラーアプリケーションにするために、その上に何を加えればよいのかをsymfonyのコミュニティは討論しました。
提案はすでに初期の段階で計画したものが含まれていました。埋め込むのに数分しか必要のない小さな追加物、おそらくは1.0のリリースのあとにすぐに追加されるものもありました。askeetは生きているオープンソースのアプリケーションを目指します。チケットを提示し、askeetのtracのシステムに考えたことを提案することを始めることができます。 パッチとあなたが望むアプリケーションの拡張を投稿することもできます。しかし数日お待ちください、アドベントカレンダーはクリスマスの前にあなたを驚かせるものをお見せします。
検索エンジンを構築する方法は?
21日目についての追加についてもっとも人気のあった提案は検索エンジンと判明しました。
Zsearchエクステンション(ApacheからのLucene検索エンジンのPHP実装)がZend社によってリリースされていたら、実装するのはたやすいことでしょう。残念なことに、Zend社はPHPフレームワークを立ち上げることが期待されているようなので、別の解決方法を探す必要があります。
外部ライブラリを統合すること(たとえば、mnoGoSearch)はおそらく1時間以上かかり、askeet固有の内容のためによい結果を得るために多くのカスタム採用が必要です。加えて、外部検索ライブラリはしばしばプラットフォームもしくはデータベース依存で、それらすべてはオープンソースで、askeetのために私たちが望まないものもあります。
MySQLデータベースは全文検索のインデックスとテキスト内容の検索を提供しますが、MyISAMテーブルに制限されます。繰り返しますと、特定のデータベースのコンポーネント上の検索エンジンをベースにすることはaskeetアプリケーションの使用の可能性を制限します。そして、これまでのところ、私たちは大規模な互換性を保持するために何でもしたいのです。
残された唯一の代替法は我々自身でPHP製の全文検索エンジンを開発することです。1時間未満になったので、始めた方がいいでしょう。
単語インデックス
最初のステップは検索インデックスを構築することです。インデックスはすべての特別な言葉の存在に索引をつけるテーブルとして見られます。たとえば、質問#34は次の特徴があるとします:
- タイトル: 私の子供のためのベストな星座は何ですか?
- ボディ: 私の夫は次の子供の星座に無関心です。しかし、私たちにはすでに蟹座の女の子と羊座の男の子がいます。この子達はとても仲がいいです。私の義理の母は好みを言いません。そこで次の赤ちゃんの星座を選ぶのは完全に自由です。どう思いますか?
- タグ: zodiac, real life, family, children, sign, astrology, signs
検索エンジンが見つけられるようにインデックスはこの質問の単語の一覧を表示するために作成されなければなりません。
インデックステーブル
インデックスは次の通りです:
| id | word | count |
|---|---|---|
| 34 | sign | 4 |
| 34 | zodiac | 4 |
| 34 | child | 2 |
| 34 | hell | 1 |
| 34 | ... | ... |
モデルをリビルドする前に、askeetのschema.xmlに新しいSearchIndexテーブルを追加します:
<table name="ask_search_index" phpName="SearchIndex"> <column name="question_id" type="integer" /> <foreign-key foreignTable="ask_question" onDelete="cascade"> <reference local="question_id" foreign="id"/> </foreign-key> <column name="word" type="varchar" size="255" /> <index name="word_index"> <index-column name="word" /> </index> <column name="weight" type="integer" /> </table>
昨日説明したように、onDelete属性は質問を削除するとこの質問に関連するSearchIndexテーブルの中のすべてのレコードが削除されることを保証します。
フレーズを単語に分割する
インデックスのビルドに使われる入力内容はセンテンス(質問タイトルとボディ)とタグのセットです。結局必要なのは単語リストです。このことはセンテンスを単語に分割することが必要であることを意味します。すべての句読法、数字は無視し、すべての単語は小文字にされます。PHPのstr_word_count()関数はトリックを行います:
// 単語に分割する $words = str_word_count(strtolower($phrase), 1); ...
ストップワード
テキスト内容のインデックスを作成するとき、"a," "of," "the," "I," "it," "you," "and,"などのいくつかの単語が無視されるようにしなければなりません。なぜなら、区別する価値がないからです。これらの単語はほとんどすべてのテキストの内容に現れ、テキスト検索を遅くさせ、ユーザーのクエリとは無関係で望ましくない結果を返します。これらの単語はストップワードとしても知られています。ストップワードは与えられた言語ごとに固有なものです。
askeetの検索エンジンのために、ストップワードのカスタムリストを使います。askeet/lib/myTools.class.phpクラスに次のメソッドを追加します:
public static function removeStopWordsFromArray($words) { $stop_words = array( 'i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', 'her', 'hers', 'herself', 'it', 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', ); return array_diff($words, $stop_words); }
ステミング
上述の例の質問において最初に気づくことは同じ語根を持つ単語が単独のものとしてみなされることです。'Children'は'sign'が'signs'に対してするように'child'のウェイトを増加させます。単語のインデックスを作成する前に、これらを言語学的なボキャブラリにおける最大の共通因数にまで変形する必要があります。これは語幹と呼ばれ、または、"屈折形態素ではなく派生接辞を含む単語の基礎部分、すなわち単語部分が屈折を通して変化しない部分を保有します"。
単語を語幹に変換するルールはたくさんあります。それらのルールはみな言語に依存しています。これまでで英語でもっとよく知られている英語の語幹化テクニックはポーターステミングアルゴリズムと呼ばれ、とても幸運なことにオープンソースのPHP 5に移植され、tartarus.orgから利用可能です。
PorterStemmerクラスはあなたの要求を完璧に満たす::stem($word)メソッドを提供します。それでは句を語幹単語の配列に変換するmyTools.class.phpにメソッドを書くことにします:
public static function stemPhrase($phrase) { // 単語に分割する $words = str_word_count(strtolower($phrase), 1); // ストップワードを無視する $words = myTools::removeStopWordsFromArray($words); // ステムワード $stemmed_words = array(); foreach ($words as $word) { // 1・2文字の単語を無視する if (strlen($word) <= 2) { continue; } $stemmed_words[] = PorterStemmer::stem($word, true); } return $stemmed_words; }
もちろん、これを動かすために、askeet/lib/ディレクトリにPorterStemmer.class.phpに設置する必要があります。
単語に重みを与える
検索結果は適切な順序で表示されなければなりません。ユーザーによって入力された単語に密接に関連する質問は最初に現れなければなりません。しかし、適切性のこのアイディアをアルゴリズムに変換できるようにするにはどうしたらよいでしょうか?いくつかの基礎的な原則を書きましょう:
- 検索された単語が質問のタイトルに現れる場合、ボディに現れた他の単語よりも、この単語は検索結果に対して高い順位で現れた方がいいでしょう。
- 質問の内容に検索単語が2つ現れる場合、ほかの場所で一度だけ単語が現れる前に検索結果はこの質問を表示します。
由来する質問部分に従って、重みを単語に与えるわけはそういうことです。重み要素は変更するために簡単にアクセス可能であり、検索エンジンアルゴリズムを微調整することを望む場合、変更できるようにするため、アプリケーションの設定ファイルに次のコードを追記します(askeet/apps/frontend/config/app.yml):
all:
...
search:
body_weight: 1
title_weight: 2
tag_weight: 3
単語に重みを適用するために、そのオリジナルの重み要素と同じ文字列の内容を単純に繰り返します:
... // 質問のボディ $raw_text = str_repeat(' '.strip_tags($question->getHtmlBody()), sfConfig::get('app_search_body_weight')); // 質問のタイトル $raw_text .= str_repeat(' '.$question->getTitle(), sfConfig::get('app_search_title_weight')); ...
基本的な単語の重みはテキストにおける出現頻度によって与えられます。array_count_values()関数は次のように手助けしてくれます:
... // フレーズのステミング $stemmed_words = myTools::stemPhrase($raw_text); // 重みつきのユニークな単語 $words = array_count_values($stemmed_words);
インデックスを更新する
質問、タグまたは回答が追加されるたびにインデックスを更新しなければなりません。MVC構造ではそれを簡単に行うことが可能で、たとえば4日目のように、トランザクションでモデルのクラスのsave()メソッドをオーバーライドする方法をすでに見ています。ですので、次のことには驚かないでしょう。askeet/lib/model/Question.phpファイルを開き次のコードを追加します:
public function save($con = null) { $con = sfContext::getInstance()->getDatabaseConnection('propel'); try { $con->begin(); $ret = parent::save($con); $this->updateSearchIndex(); $con->commit(); return $ret; } catch (Exception $e) { $con->rollback(); throw $e; } } public function updateSearchIndex() { // 現在の質問に関する既存のSearchIndexエントリを削除する $c = new Criteria(); $c->add(SearchIndexPeer::QUESTION_ID, $this->getId()); SearchIndexPeer::doDelete($c); // 質問のそれぞれの単語用の新しいエントリを作る foreach ($this->getWords() as $word => $weight) { $index = new SearchIndex(); $index->setQuestionId($this->getId()); $index->setWord($word); $index->setWeight($weight); $index->save(); } } public function getWords() { // 本体 $raw_text = str_repeat(' '.strip_tags($this->getHtmlBody()), sfConfig::get('app_search_body_weight')); // タイトル $raw_text .= str_repeat(' '.$this->getTitle(), sfConfig::get('app_search_title_weight')); // タイトルと本体のステミング $stemmed_words = myTools::stemPhrase($raw_text); // 重みつきのユニークな単語 $words = array_count_values($stemmed_words); // タグを追加する $max = 0; foreach ($this->getPopularTags(20) as $tag => $count) { if (!$max) { $max = $count; } $stemmed_tag = PorterStemmer::stem($tag); if (!isset($words[$stemmed_tag])) { $words[$stemmed_tag] = 0; } $words[$stemmed_tag] += ceil(($count / $max) * sfConfig::get('app_search_tag_weight')); } return $words; }
質問にタグが追加されるたびに質問インデックスを更新しなければなりません。同じようにTagモデルオブジェクトのsave()メソッドをオーバーライドします:
public function save($con = null) { $con = sfContext::getInstance()->getDatabaseConnection('propel'); try { $con->begin(); $ret = parent::save($con); $this->getQuestion()->updateSearchIndex(); $con->commit(); return $ret; } catch (Exception $e) { $con->rollback(); throw $e; } }
インデックスビルダーをテストする
インデックスをビルドする準備ができました。データベースを再投入して初期化します:
$ php batch/load_data.php
インデックス作成がすべてうまくいったかどうかチェックするためにSearchIndexを調べられます:
| id | word | weight |
|---|---|---|
| 10 | blog | 6 |
| 9 | offer | 4 |
| 8 | girl | 3 |
| 8 | rel | 3 |
| 8 | activ | 3 |
| 10 | activ | 3 |
| 9 | present | 3 |
| 9 | reallif | 3 |
| 11 | test | 3 |
| 12 | test | 3 |
| 13 | test | 3 |
| 8 | shall | 3 |
| 8 | tonight | 2 |
| 8 | girlfriend | 2 |
| .. | ..... | .. |
検索機能
ANDもしくはOR?
'AND'と'OR'検索の両方を管理するには検索機能が必要です。たとえば、ユーザーが'family zodiac'を入力すると、2つの用語が現れる選択肢('AND'の場合)、もしくは少なくとも1つの用語がすべて現れるすべての質問の選択肢('OR'の場合)だけが見えなければなりません。問題はこれらのオプションが異なるクエリを必要とすることです:
// ORクエリ SELECT DISTINCT question_id, COUNT(*) AS nb, SUM(weight) AS total_weight FROM ask_search_index WHERE (word = "family" OR word = "zodiac") GROUP BY question_id ORDER BY nb DESC, total_weight DESC // ANDクエリ SELECT DISTINCT question_id, COUNT(*) AS nb, SUM(weight) AS total_weight FROM ask_search_index WHERE (word = "family" OR word = "zodiac") GROUP BY question_id HAVING nb = 2 ORDER BY nb DESC, total_weight DESC
HAVINGキーワード(たとえばw3schoolsで説明されています)のおかげで、ANDSQLクエリはORクエリよりも一行だけ長いだけです。GROUP BYがidカラムにあり、1つの質問で1つの単語に対するインデックスの存在は1つしかないので、question_idが2倍返された場合、質問が'family'と'zodiac'の両方にマッチするからです。すばらしいでしょう?
検索メソッド
検索機能を動かすために、内容に関して同じ扱いを検索フレーズに適用する必要があるのでユーザーによって入力された単語はインデックスに存在する同じ種類の語幹に変換されます。外部制約を伴わない質問のセットを返すので、これをQuestionPeerのメソッドとして実装することを決めました。
検索結果をページ分割する必要があります。複雑なリクエストを使うので、sfPropelPagerオブジェクトはここでは採用せず、オフセットを使い手動でページ分割します。
覚えておくことがいくつかあります: askeetはuniverseで動作します(18日目のチュートリアルの問題でした)このことはuniverseでユーザーがaskeetをブラウジングする場合に検索機能は現在のapp_permanet_tagでタグづけされた質問のみを返さなければなりません。
これらすべての条件はSQLクエリを少し読みづらくしますが、上で説明されたものと大きくは異なりません:
public static function search($phrase, $exact = false, $offset = 0, $max = 10) { $words = array_values(myTools::stemPhrase($phrase)); $nb_words = count($words); if (!$words) { return array(); } $con = sfContext::getInstance()->getDatabaseConnection('propel'); // 基本クエリを定義する $query = ' SELECT DISTINCT '.SearchIndexPeer::QUESTION_ID.', COUNT(*) AS nb, SUM('.SearchIndexPeer::WEIGHT.') AS total_weight FROM '.SearchIndexPeer::TABLE_NAME; if (sfConfig::get('app_permanent_tag')) { $query .= ' WHERE '; } else { $query .= ' LEFT JOIN '.QuestionTagPeer::TABLE_NAME.' ON '.QuestionTagPeer::QUESTION_ID.' = '.SearchIndexPeer::QUESTION_ID.' WHERE '.QuestionTagPeer::NORMALIZED_TAG.' = ? AND '; } $query .= ' ('.implode(' OR ', array_fill(0, $nb_words, SearchIndexPeer::WORD.' = ?')).') GROUP BY '.SearchIndexPeer::QUESTION_ID; // ANDクエリ? if ($exact) { $query .= ' HAVING nb = '.$nb_words; } $query .= ' ORDER BY nb DESC, total_weight DESC'; // プリペアードステートメント $stmt = $con->prepareStatement($query); $stmt->setOffset($offset); $stmt->setLimit($max); $placeholder_offset = 1; if (sfConfig::get('app_permanent_tag')) { $stmt->setString(1, sfConfig::get('app_permanent_tag')); $placeholder_offset = 2; } for ($i = 0; $i < $nb_words; $i++) { $stmt->setString($i + $placeholder_offset, $words[$i]); } $rs = $stmt->executeQuery(ResultSet::FETCHMODE_NUM); // 結果を管理する $questions = array(); while ($rs->next()) { $questions[] = self::retrieveByPK($rs->getInt(1)); } return $questions; }
メソッドは適切に並べられたQuestionオブジェクトのリストを返します。
検索フォーム
検索フォームは常に利用できなければならないので、サイドバーに設置する方法を選びます。2つの離れたサイドバーがあるので、これらは同じパーシャルを格納します:
// askeet/apps/frontend/modules/sidebar/templates/内のdefaultSuccess.phpとquestionSuccess.phpに追加する <h2>find it</h2> <?php include_partial('question/search') ?> // 次のコードを作る askeet/apps/frontend/modules/question/templates/_search.phpフラグメント <?php echo form_tag('@search_question') ?> <?php echo input_tag('search', htmlspecialchars($sf_params->get('search')), array('style' => 'width: 150px')) ?> <?php echo submit_tag('search it', 'class=small') ?> <?php echo checkbox_tag('search_all', 1, $sf_params->get('search_all')) ?> <label for="search_all" class="small">search with all words</label> </form>
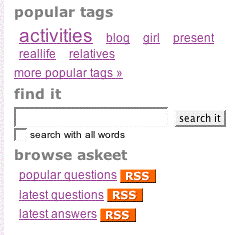
@search_questionルールはrouting.ymlで定義されなければなりません:
search_question:
url: /search/*
param: { module: question, action: search }
question/searchアクションが何を行うのかご存じですか?ほとんど何もしていません。多くの仕事は上記のQuestionPeer::search()メソッドで取り扱われているからです:
public function executeSearch () { if ($this->getRequestParameter('search')) { $this->questions = QuestionPeer::search($this->getRequestParameter('search'), $this->getRequestParameter('search_all', false), ($this->getRequestParameter('page', 1) - 1) * sfConfig::get('app_search_results_max'), sfConfig::get('app_search_results_max')); } else { $this->redirect('@homepage'); } }
アクションは::search()メソッドのためにpageリクエストパラメータをoffsetに翻訳しなければなりません。app_search_results_maxはページごとの結果数で、通常はapp.ymlファイルで定義されたアプリケーションパラメータです:
all:
search:
results_max: 10
検索結果を表示する
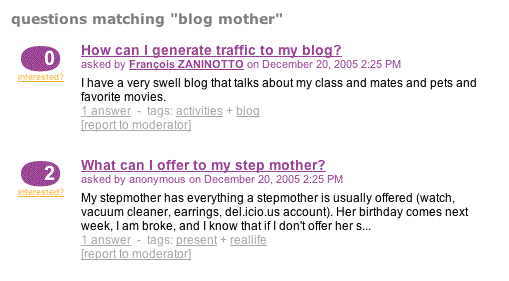
もっともハードな部分の仕事が終わり、askeet/apps/frontend/modules/qeustion/templates/searchSuccess.phpに検索結果を表示しなければなりません。クエリを軽量に保つ本当のページ分割を実装していなかったので、テンプレートは全体の結果数について何も情報を持っていません。ページ分割は結果数がページごとの結果数に等しい場合に結果リストの底に'more results'リンクを表示します:
<?php use_helper('Global') ?> <h1>questions matching "<?php echo htmlspecialchars($sf_params->get('search')) ?>"</h1> <?php foreach($questions as $question): ?> <?php include_partial('question/question_block', array('question' => $question)) ?> <?php endforeach ?> <?php if ($sf_params->get('page') > 1 && !count($questions)): ?> <div>There is no more result for your search.</div> <?php elseif (!count($questions)): ?> <div>Sorry, there is no question matching your search terms.</div> <?php endif ?> <?php if (count($questions) == sfConfig::get('app_search_results_max')): ?> <div class="right"> <?php echo link_to('more results »', '@search_question?search='.$sf_params->get('search').'&page='.($sf_params->get('page', 1) + 1)) ?> </div> <?php endif ?>
ああ、そうです、これは最後のサプライズです。コードは複数の場所で再利用されるので、_question_block.phpを作成する質問テンプレートを少しリファクタリングしました。このフラグメントをソースリポジトリで見ることができます。新しいものはありません。しかしコードをクリーンに保つ手助けになります。
それではまた明日
我々のニーズを完璧に採用したよい検索エンジンを構築するのに約1時間かかりました。手軽で、速く効率的です。適切な検索結果を表示します。微調整する可能性がなく、同じジョブをこなす外部ライブラリを統合させることを望みますか?
そうでなかったら、おそらくはsymfonyの方法論を考えることができるようになっています。 このチュートリアルを理解したのであれば、検索エンジンに質問への回答インデックスを追加できます。質問と提案はaskeetフォーラムで歓迎します。とりわけ、同じような質問がすでにあるのであれば、askeetに新しい質問を作らないでください 今は検索エンジンがあるので、言い訳できませんよ!
This work is licensed under the Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 Unported License license.